Most Important Event at Crossfit Open
Background
The CrossFit Open takes place every year as the first qualifying stage of the CrossFit Games (which is used to determine the “Fittest on Earth). The athletes that finish in the top 20 in the world automatically qualify for the CrossFit Games. The CrossFit Open consists of 5 unique workouts (see workouts here) and your overall CrossFit Open score consists of how you finished on all 5 workouts (see leaderboard here).
Problem
Which of the 5 events had the most impact on the overall leaderboard? Note this analysis is initially just for male athletes I will be doing female athletes next and comparing the results.
Analysis
I started by scraping the scores from the top 500 male athletes (by overall finish) from the CrossFit Open leaderboard and ended up with the following Pandas DataFrame:
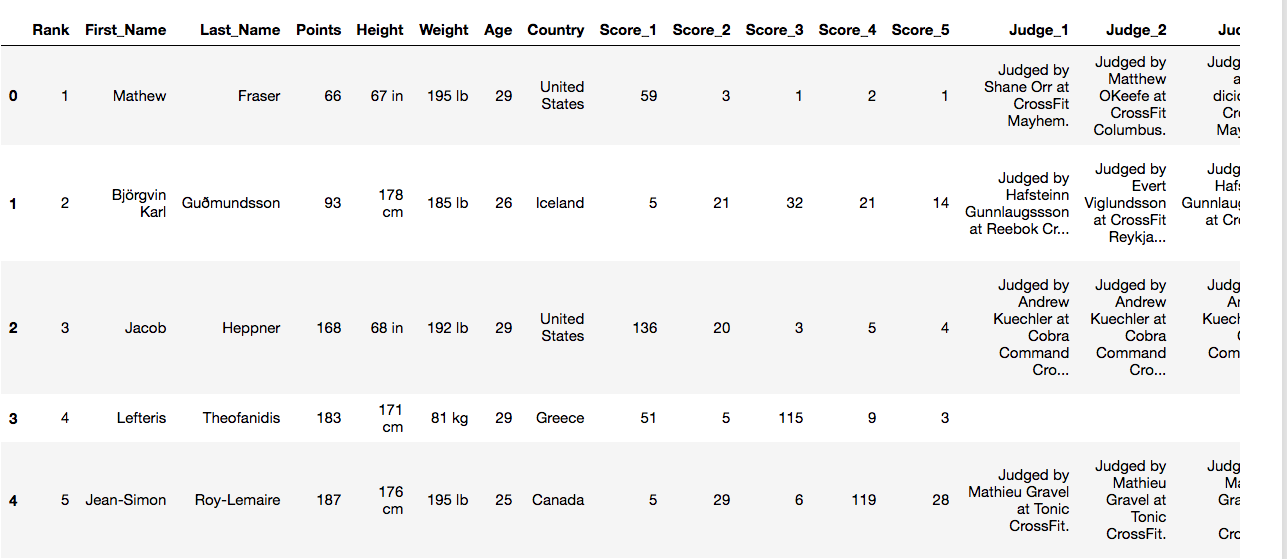
I am interested in the following features:
- Rank - Overall Rank athlete finished in the CrossFit Open (lower is better)
- Score_1 - Overall Rank athlete finished in the first workout (lower is better). Event 1 will also be called 19.1
- Score_2 - Overall Rank athlete finished in the second workout (lower is better). Event 2 will also be called 19.2
- Score_3 - Overall Rank athlete finished in the third workout (lower is better). Event 3 will also be called 19.3
- Score_4 - Overall Rank athlete finished in the fourth workout (lower is better). Event 4 will also be called 19.4
- Score_5 - Overall Rank athlete finished in the fifth workout (lower is better). Event 4 will also be called 19.5
Initially, I made scatter plots of each event vs the overall rank to see if there were any obvious trends.
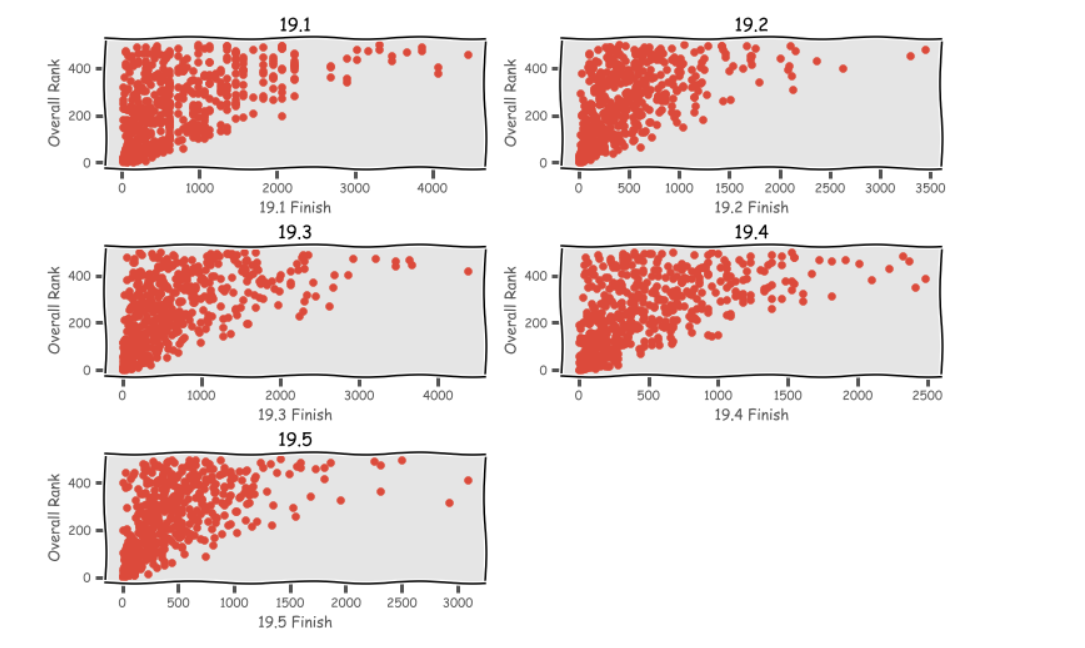
All the scatter plots look really similar, so similar that I had to double check my code to make sure I wasn’t using the same data for each subplot. Let’s look at the Pearson correlation coefficient to see if there is any difference in the relationship between the different workouts and the overall rank.
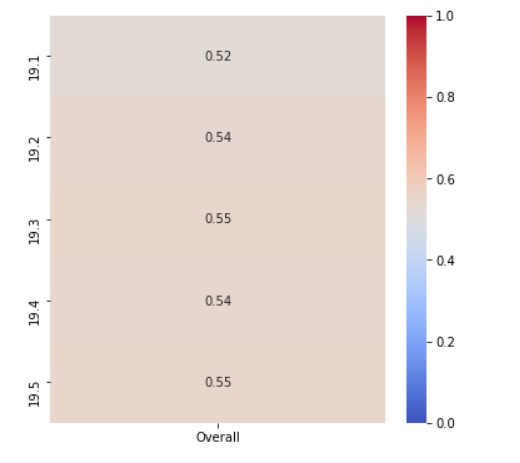
All of the correlation coefficients are really similar between 0.52 and 0.55. Next I want to try permutation importance to see if that can better determine which is the most important workout. Permutation measures how much a score changes when a feature is no longer available.
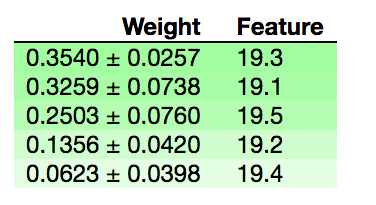
This shows that after multiple shuffles the \(R^2\) for 19.3 changed on average 0.35, while the average \(R^2\) for 19.4 only changed 0.06. This means that the event 19.3 had a big impact on predicting their overall score, while 19.4 did not have much of an impact on predicting their overall score. This could be caused by a lot of different factors - my guess is that 19.3 was a workout that was a “seperator”. In that if you score badly on 19.3, you are going to do badly overall relatively.