Interpretable Classifiers Using Rules and Bayesian Analysis - Building a Better Stroke Prediction Model
Link to Paper
What did the authors try to accomplish?
The authors show that using a rule-list-based model, an interpretable model, they are able to get similar results to top algorithms. They compare the results of their model to a common approach for assigning the risk to stroke patients.
What were the key elements of the approach?
The authors used what they described as Bayesian Rule lists to come up with rules for predicting the risk of stroke patients. This produced lists the following:
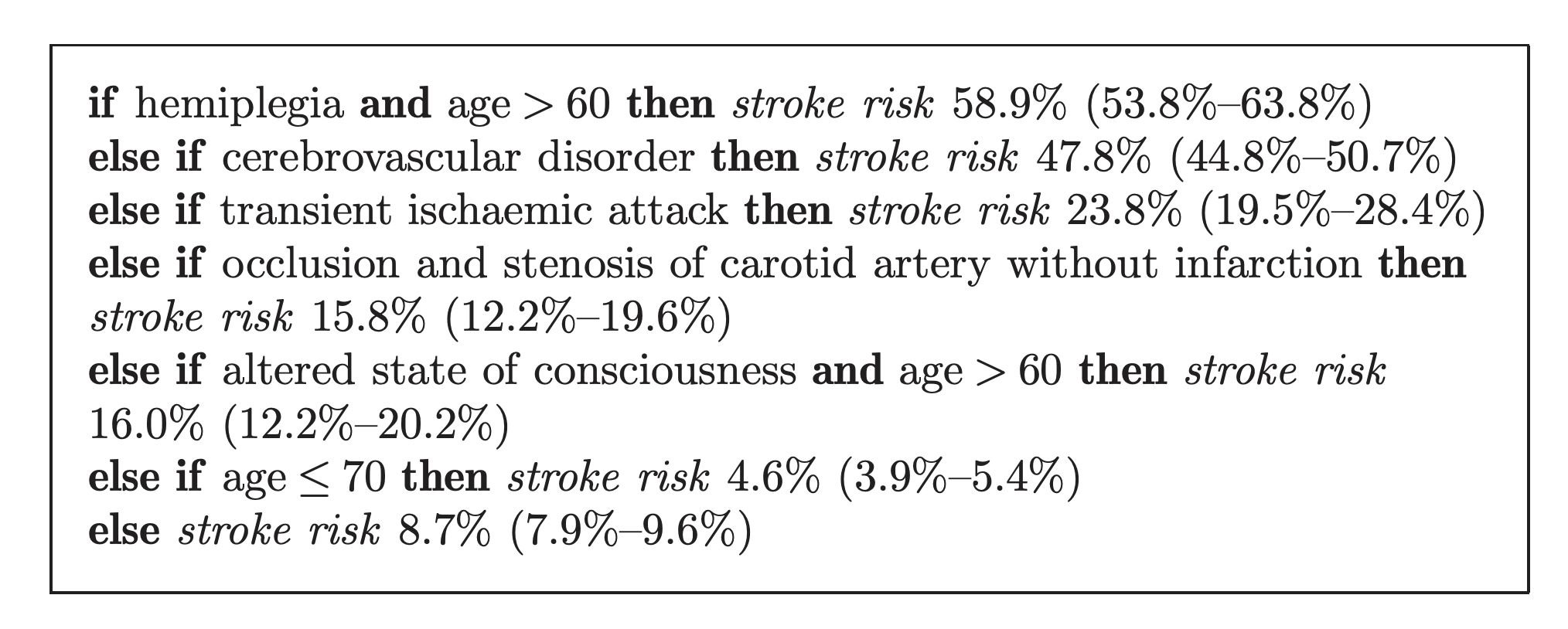
This shows that if someone has hemiplegia and is over the age of 60, their stroke risk is 58.9% with a 95% confidence interval of 53.8%-63.8%. In an effort to make the rules as easily explainable as possible, they focused on making each of the rules sparse.
What can you use yourself?
Rule-list type algorithms can have many use cases from making predictions to gaining insights from the model. I personally see a bigger opportunity from gaining insights, rule-list-based algorithms are able to quantify the importance of interaction features that are often difficult to find during EDA. In my experience with marketing analytics, business stakeholders are interested in what drives their customers and due to large class imbalances, traditional models can struggle with this; while rule-based algorithms can identify smaller subsets of the data where the probability of purchasing a product is higher.
What other references do you want to follow?
There are a few techniques for making rule-based algorithms in Python. One is skope-rules and another is pycorels. I have a Google Colab notebook showing them being used here
Note: I used Google Colab due to some installation issues with PyCorels. I was able to install skope-rules locally.